
Load balancers help disperse traffic across a fleet of servers using different algorithms. Often we use load balancers to protect our servers from being overwhelmed by limiting the number of concurrent requests to each server. Load balancers are built to manage a huge number of connections while backend servers might not be that capable which can lead to degradation and even downtime. When there are more requests than the server can take, a requests queue starts to form up. In case of a surge, some requests can wait in the queue longer than usual and even timeout with 503 while waiting to be processed. But, what if we want to prioritize some requests so that they don’t wait in the same queue with all other requests?
The use case for request prioritization
In our case, we have a CPU-bound service. Unlike I/O-bound services, like APIs reading from some external DB, CPU-bound services are almost entirely limited to CPU capacity of the machine which hosts the service. Service like that can serve in parallel as many requests as there are CPU cores. Technically, it can process more than that in parallel, but requests will take longer since there is just no available CPU time. If the server hosting this kind of service has 2 CPU cores, we can limit to 2 parallel requests in the load balancer. This will form the queue as soon as more than 2 requests are being processed at the same time.
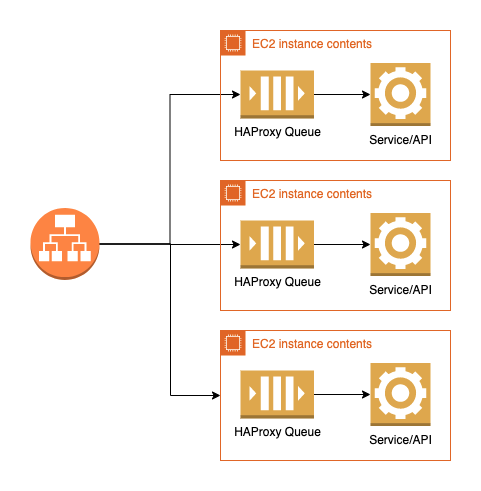
Next, we have AWS ALB accepting all requests from the outside. Unfortunately, ALB doesn’t support request queueing so it just routes all requests to servers (targets). At each server we have HAProxy accepting connections, balancing requests across workers in the same server (exact count of workers depends on the number of cores) and making queue if there are more requests than we can serve in parallel. In case of request surge, request queue forms up at HAProxy level. In that same queue there are health check requests from ALB, waiting to be processed (ALB periodically sends health check requests to ensure targets are healthy). If service doesn’t respond to those health checks on time, after several tries, the instance will be marked as unhealthy. An unhealthy instance will be selected for recreation by Autoscaling Group (ASG). One instance less in rotation means more load during surge for other instances. Following this principle, in a short time, all instances of such service can be kicked out of rotation, scheduled for recreation which will left region with 0 instances serving traffic (until ASG provisions new instances).
Request serving priority comes to help
We solved this challenge by adding higher priority for the processing of health checks. This means that regular traffic can wait in the queue while we process all health checks as soon as they arrive. That makes sure that instance responds to health checks even during request surge by going around of all other requests. Instead of kicking instance out of rotation, by not responding to health checks, the request spike will just cause some requests to timeout (in the worst-case scenario).

For this purpose, we use 2 HAProxy backends, regular backend and one for the health checks. In the frontend section we select backend for each request like in this example:
use_backend backend_1 if req_regular
use_backend backend_1_health_check if req_health_check
We defined two backends like this (some settings are omitted for brevity), both routing to the same set of workers within 1 instance:
backend backend_1 timeout queue 5s default-server weight 1 maxconn 2backend_1_health_check timeout queue 20s default-server weight 1 maxconn 10
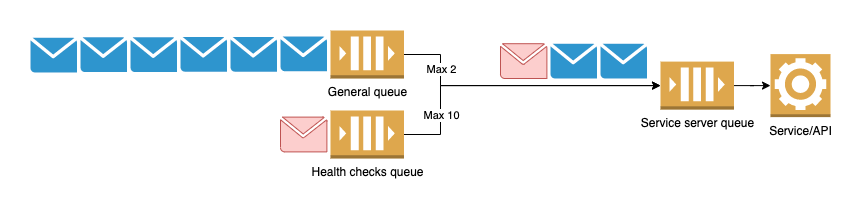
Instead of increasing priority for health checks (because that’s not possible as such), we defined 2 queues. One for all traffic and one for health checks traffic. HAProxy will let requests from this queue downstream respecting maxconn to service which has another queue. This ensures that, in the worst-case scenario, we’ll always have a health check request 3rd in line to be processed (check chart above).
Other use cases
Although not many services out there are entirely CPU-bound with the low number of workers so that health checks need to be prioritized, this technique can be used for other use cases. By controlling maxconn in the backend section you can control the ratio of specific requests and implement “soft” throttling where some type of requests are determined to wait longer compared to others.
Some extra notes:
- low maxconn is not good for I/O-bound services. It’s always good to understand what kind of workload is being balanced and configure accordingly
- queue has some low overhead in terms of latency. In our case, we measured ≤ 1ms overhead which was completely acceptable
- nginx supports similar queueing mechanism but only in Plus version (https://nginx.org/en/docs/http/ngx_http_upstream_module.html#queue)
- prioritization/QoS can be also implemented by having separate backends for high and low priority requests. For example, a higher number of faster servers serving high priority requests and a smaller number of slower servers serving low priority requests. In that case, HAProxy should be placed in front of the fleet and not in an instance as in the example above.
- keeping the queue at backend (HAProxy backend, just before services), helps with better utilization of workers in the node.
- Another advantage of this setup, not covered here, is the ability to retry requests on other workers in case of failure of some sort (https://www.haproxy.com/blog/haproxy-layer-7-retries-and-chaos-engineering/).
- Some other examples of priority queues — https://www.haproxy.com/blog/application-delivery-controller-and-ecommerce-websites/
Update: Alternative method for request prioritization
An alternative method, and probably preferred, to prioritize requests is to use a set-priority-class directive which is available from version 1.9 (Thanks to Daniel for pointing it out).
Usage:
http-request set-priority-class <expr> [ { if | unless } <condition> ]
This is used to set the queue priority class of the current request.
The value must be a sample expression which converts to an integer in the
range -2047..2047. Results outside this range will be truncated.
The priority class determines the order in which queued requests are
processed. Lower values have higher priority.
Using this directive, the solution to prioritizing health checks would like something like this:
http-request set-priority-class int(1) if req_health_check
http-request set-priority-class int(10) if req_regular
Want to learn more about optimizing on-site search to drive real business metrics?
For years, retailers have optimized search solely on “relevance,” hoping the results that users want to see (and the results that drive important business metrics) appear at the top.
This is exactly wrong — and it’s not how companies like Google and Amazon optimize their search.
